Inference with Reference: Lossless Acceleration of Large Language Models 閱讀筆記
前言
因為現在的decoder過一次MODEL只能在生成下一個token(下圖紅色的部分),導致生成一句話需要過多次的模型,因此速度緩慢

目前的decoder:
- 目前的transformer LM主要在做生成的時候是靠 Stepwise Decoding in Autoregresive Language Models,每次把input text中前面的部分丟到模型中去預測下一個字,因此需要重複過很多次模型,ex, 今 → 天, 今天 → 天, 今天天 → 氣, 今天天氣 → 真, 今天天氣真 → 好

- Greedy decoder: 最常見的decoder每次decode的時候都選機率最高的那個token作為預測的字

本篇做accelerator的啟發:
- 觀察到LLM的output很大一部分的output會來自於input,因此以此為背景提出可以加速至少兩倍的方法
- 本篇舉出3個常見的LLM例子:
(a) Retrieval-augmented : 根據找回的相關文章做統整
(b) Cache-assisted:根據過去的對話紀錄,繼續往下作答
(c) Multi-turn conversations: 多輪對話

LLMA: Inference with Reference

- 給予一連串的參考文本D,給予prompt input x希望根據D生成回答 y ,在假設答案中大部分的回答的token會出現在D中
- 在生成第i個output的時候,會去看前n個生成的token是否有match 文本D 中的其中一筆資料d,如果沒有的話就使用一般的decoder,當match多筆的時候,選擇最長的d,都一樣長的話就random選
- (step 3) 如果文本d中(pos − n, pos) 被mapping到的話,直接假設模型的輸出會有很高的機率繼續follow 文本 d 後的tokens,因此把後k個tokens加入模型的輸入中
- (step 3) 因此將模型的輸入加入文本d的後k個字,讓模型可以在一次的decode中生成 k + 1 個 tokens ,達到加速的目的:

- (圖中勾勾跟叉叉) 此外會有驗證機制去棄用那些驗證生成的token是否可以使用,驗證機制是去看 LLMA 生成的 tokens 是否跟 input 進去的document 的 token 一樣,如果不一樣的話就直接棄用該字以及棄用其後面的輸出
- 整體的 sudo code如下,n 為參數 match lengths 代表已生成的答案中跟d mapping到n個token相同時會啟用LLMA的機制, k 為參數 copy lengths 代表啟動LLMA後會copy幾個token, N 為輸出長度限制:

Experiment
使用資料集 MS-MARCO ,一個 1 M 的資料集,問句是由bing search engine 收集到的
- query: 問句
- passages: 包含10由bing search找回的相關段落
- query_type: 透過訓練的分類器把query分為:{LOCATION, NUMERIC, PERSON, DESCRIPTION, ENTITY}
- answers: 大多只包含一個答案,約有1%的資料包含2個以上的答
- wellFormedAnswers: 約有180k的資料有用更好的文法等rewritten answers
{
"answers":["A corporation is a company or group of people authorized to act as a single entity and recognized as such in law."],
"passages":[
{
"is_selected":0,
"url":"http:\/\/www.wisegeek.com\/what-is-a-corporation.htm",
"passage_text":"A company is incorporated in a specific nation, often within the bounds of a smaller subset of that nation, such as a state or province. The corporation is then governed by the laws of incorporation in that state. A corporation may issue stock, either private or public, or may be classified as a non-stock corporation. If stock is issued, the corporation will usually be governed by its shareholders, either directly or indirectly."},
...
}],
"query":". what is a corporation?",
"query_id":1102432,
"query_type":"DESCRIPTION",
"wellFormedAnswers":"[]"
}將該資料集對應此篇論文的內容處理成:
- input prompt x :query
- target generation result y :answers
- reference documents D : passages
Application Scenarios
在每一個Scenarios都使用200個(x,y,D)的pair,其中100筆用來調整超參數以及prompt,另外100筆用來驗證
Retrieval-Augmented Generation (RAG):給予query以及相關的文本D,生成answer y,使用 E5 (Wang et al., 2022) 由MS-MARCO段落中找回最相似的10筆作為D,透過定好的template生成intpu x
Cache-Assisted Generation (CAG): 將MS-MARCO的query透過davinci-003生成4筆相似的query去模擬CAG的情況,並取得答案,將這些生成的相似的QA pair作為D
Multi-turn Conversation with LLMs:多輪對話,將前幾輪對話內容視為D。但論文在後續沒有針對這個情境的實驗
Experiment Design
- 7B and 13B models 用一張 NVidia 32G V100 GPU,
- 30B model 用四張 NVidia 32G V100 GPUs
- 全部實驗都使用greedy-decoding
- 使用的prompt

- 在兩種Scenarios: Retrieval, Cache下的 n( match lengths), k(copy length)的設置

Experiment
- 實際速度比較
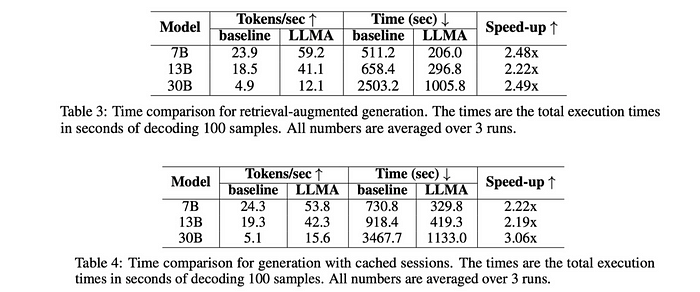
- match length n 跟 copy length k對速度的影響,基本上就是n越小k越大,速度越快

心得
優點:
- 是一個從演算法層面上改良的方法,不需要改變原本的模型就可以做到decoder加速
- 理論上也不是只能用在LLM,只要是用Stepwise Decoding in Autoregresive Language Models的方法都可以用,像是T5
- 沒有硬體限制,不會像bf16加速等需要特定版本GPU
- 跟其他的加速方式可以併行使用 ex quantize 等
缺點:
- 感覺目前有點像先放到arXiv上占位子,實驗的部分感覺有點少,且感覺這個方法可能會影響結果的準確度,但實驗的數據量有點不夠,且沒有對是否會影響decoder結果做探討
- 需要調整參數match and copy lengths n and k
- 只適合 output 的 token 會大量參考 input 資訊的 task
此外目前還沒有找到直接可用的code ,有看起來是有早一點的seq-to-seq的版本的code,在2022 Lossless Acceleration for Seq2seq Generation with Aggressive Decoding 有分成兩種模式,感覺本篇是可以參考使用 IAD 的decoder的程式碼
- 1) Input-guided Aggressive Decoding (IAD) : 7×∼9× speedup on Grammatical Error Correction and Text Simplification tasks
- 2) For Generalized Aggressive Decoding (GAD): 3×∼5× speedup on Machine Translation and Abstractive Summarization